wget -O - http://apt.hamonikr.org/hamonikr.key | sudo apt-key add -
sudo bash -c "echo 'deb https://apt.hamonikr.org jin main upstream' > /etc/apt/sources.list.d/hamonikr-jin.list"
sudo bash -c "echo 'deb-src https://apt.hamonikr.org jin main upstream' >> /etc/apt/sources.list.d/hamonikr-jin.list"
sudo apt update
# 한글만 사용하고 싶은경우
sudo apt install nimf nimf-libhangul
# 일본어, 중국어 등 다른언어를 사용하고 싶은경우
sudo apt install libnimf1 nimf nimf-anthy nimf-dev nimf-libhangul nimf-m17n nimf-rime
im-config -n nimf
sudo reboot now분류 전체보기
- Ubuntu에 nimf 한글입력기 설치하기 2020.06.05
- Ubnutu apt update시 Certificate verification failed 에러 처리 2020.06.03
- model.fit을 history로 받아 loss, acc그래프 그리기 2020.05.15
- 딥러닝으로 고양이와 개를 구분해보자. 2019.12.20 7
Ubuntu에 nimf 한글입력기 설치하기
2020. 6. 5. 09:15
Ubnutu apt update시 Certificate verification failed 에러 처리
2020. 6. 3. 15:27
echo -n | openssl s_client -connect 접속하고자하는주소:443 | \
sed -ne '/-BEGIN CERTIFICATE-/,/-END CERTIFICATE-/p' | \
sudo tee -a '/usr/local/share/ca-certificates/download_01_org.crt'
sudo update-ca-certificatesmodel.fit을 history로 받아 loss, acc그래프 그리기
2020. 5. 15. 08:22
# summarize history for accuracy
plt.plot(history.history['accuracy'])
plt.plot(history.history['val_accuracy'])
plt.title('model accuracy')
plt.ylabel('accuracy')
plt.xlabel('epoch')
plt.legend(['train', 'test'], loc='upper left')
plt.show()
# summarize history for loss
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.title('model loss')
plt.ylabel('loss')
plt.xlabel('epoch')
plt.legend(['train', 'test'], loc='upper left')
plt.show()딥러닝으로 고양이와 개를 구분해보자.
2019. 12. 20. 09:42
다른 AI와는 다르게, 비전과 일부 언어쪽은 헤비한 GPU서버 사용을 요구해서,
AI를 학습하다가, 조금만 깊이 들어가면 노트북으로는 어림도 없는 지경에 이르게 됩니다.
일반적인 데이터분석과는 달리, 이미지 데이터는 이미지 한장만 하더라도 많은 정보를 담고 있어서
상대적으로 학습 데이터의 스케일이 크고, 학습에 필요한 연산의 규모가 어마어마 합니다.
[사전조건]
간단한 파이썬,
주피터 노트북 사전설치
시프트키와 엔트를 동시에 누를 수 있는 두 손.
자...이제 한번 해보시죠.
이제부터의 명령어는 주피터 노트북을 실행한 상태에서, 브라우저에서 입력하는 명령어 입니다.
0. 개, 고양이 데이터 준비
Datasets : https://www.kaggle.com/c/dogs-vs-cats/data
Dogs vs. Cats
Create an algorithm to distinguish dogs from cats
www.kaggle.com
첨부 파일을 다운받아서 아래 구조로 저장을 합니다.
(jupyter notebook파일과 같은 경로에 저장하세요)
-- data ---- train (학습을 위한 고양이, 개사진 25,000장)
|__ test1 (테스트를 위한 고양이, 개 사진 25,000장)
1. 우선 필요한 패키지를 설치 합니다.
keras에 대한 내용은 본 게시판 제 다른글을 읽어보면 개략적으로 나옵니다.
keras는 백엔드로 tensorflow를 사용하기 때문에, tensorflow까지 자동으로 설치가 됩니다.
그리고 학습데이터를 데이터프레임(데이터의 구조가 엑셀같은 표 형태로 구성)형태로 변환하고 연산하기 위한 pandas가 설치 되어야 하고,
배열 연산을 위한 numpy, 이미지 처리를 위한 image 패키지, 그리고 매트릭스를 그래프로 나타내기 위한 matplotlib,
마지막으로 수치연산을 위한 패키지인 scikit-learn을 설치 합니다.

2. warning 출력 off
주피터 노트북 셀 실행시 주황색으로 warning이 많이 뜨는데, 보기 싫으니 출력하지 말라고 합니다.

3. 필요한 패키지 import
본 알고리즘 실행에 필요한 패키지들을 import하고,
0번에서 압축 푼 데이터가 잘 저장 되어 있는지 확인 합니다.
4. 글로벌 변수를 선언 합니다.
앞서 압축 풀어놓은 이미지의 가로크기, 세로크기, 사이즈(128x128)와
채널(칼라 사잔이므로R, G, B세개)을 정의 해 놓습니다.
나중에 convolution연산 시 channel정보가 필요하므로, 미리 정의해 놓습니다.

5. 파일명과 정답 설정
압축 푼 디렉토리 중, train디렉토리에는 dogxxx.jpg, catxxx.jpg등, 개와 고양이를 파일 이름으로 구분짓도록
파일이 저장되어 있습니다.
이를 구분하여 개에 해당되는 파일명과 정답('개', 1)을, 그리고 고양이에 해당되는 파일명과 정답('고양이', 0)을
dataframe에 저장해 놓습니다.

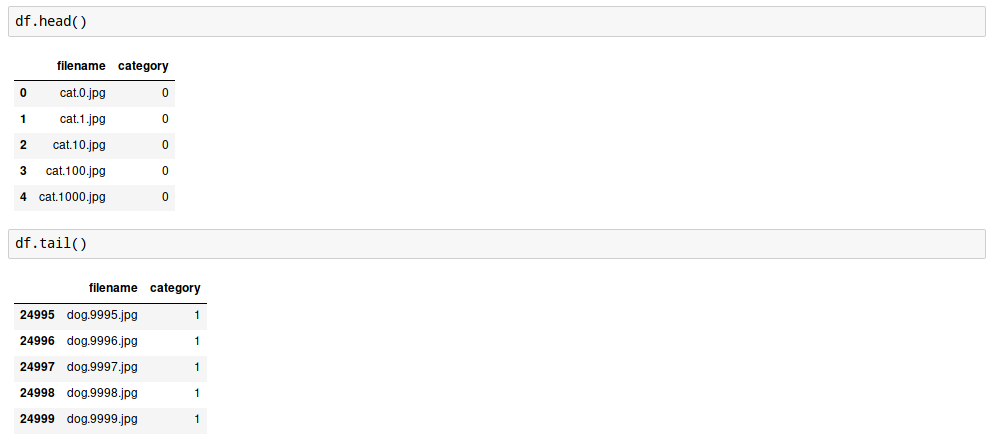
6. 저장이 잘 되어 있는지 확인해 봅니다.
데이터 셋의 제일 앞 5개와 제일 뒤 5개를 샘플링 해서 살펴봅니다.
파일 이름이 고양이로 시작된건 category가 0으로,
파일 이름이 dog으로 시작되는 파일은 category가 1로 잘 저장이 되어 있군요. :-)
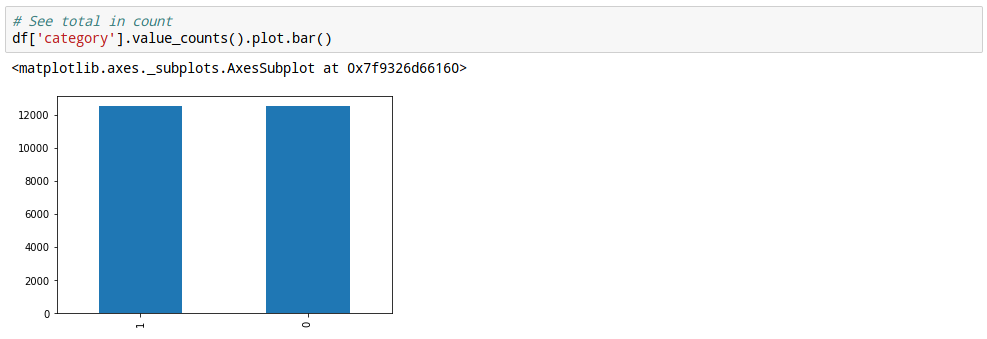
7. 데이터 balance확인.
분류 문제이 있어서, 각 category별 데이터가 고루 분포가 되어 있어야 학습이 잘 됩니다.
즉, 데이터 내에 개와 고양이가 균일하게 분포가 되어 있는지 확인을 합니다.
보니까, 고르가 잘 분포가 되어 있는거 같네요.
8. Sample데이터 확인
데이터 디렉토리중 임의로 하나를 뽑아서 확인 합니다.
아베...아니, 개가 잘 표시 되는군요.

9. 신경망 모델 구성
모델 구성은...기본적인 룰이 있긴 하지만, 여러번 구조를 바꿔가며,
잘 맞추는 모델이 나올때까지 구조를 변경시키는 것 입니다.
물론, 훌륭하신 석학들이 미리 다 해보고 잘 되는 구조를 공개해 놓은걸 가져다 쓰는게 제일 좋습니다.
우리에겐 좋은 구조를 찾기 위한 100대이상의 GPU서버를 가진 연구실이 없기 때문이죠.
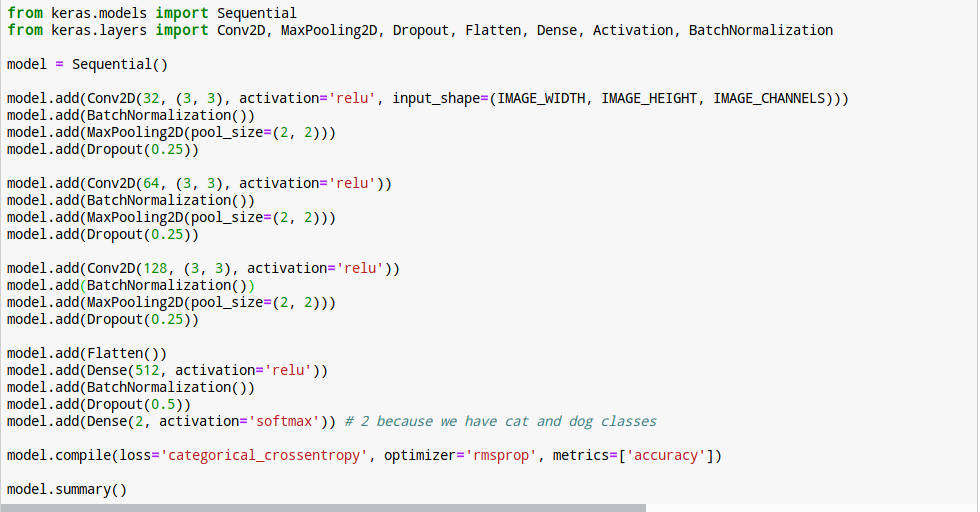
10. 신경망 구조를 살펴봅니다.
아래와 같은 구조로 생겼는데, 약 천이백만개의 파라미트를 학습해야 하는군요.
학습데이터(개, 고양이사진)이 제일 위로 들어와서 제일 아래로 나가는 구조 입니다.
제일 처음 conv2d layer의 shape를 보면 (None, 126, 126, 32) 이렇게 되어 있는데,
가운데 126, 126 숫자 두개가 바로 입력되는 개, 고양이 사진의 가로, 세로 크기 입니다.
제일 아래 Dense Layer에 보면 shape에 숫자 2가 있는데, 이게 바로 개냐 고양이냐 하는 두가지 케이스가
있기 때문에 shape가 2로 된 것 입니다.

11. 콜백 정의
음..콜백은 다 아실거고...
우선 조기종료(Early Stopping)와 학습율 하향조정을 위해 두 콜백 클래스를 import합니다.

12. Early Stopping 정의
Early Stopping이 뭐냐 하면...
전체 개, 고양이 데이터가지고 조금씩 나눠서 여러차례 학습을 하는데,
잘 학습되다가 어느시점 지나면 정확도가 오히려 떨어지는 case가 발생합니다.
이때 10번까지 참다가, 10번 지나서도 계속 떨어지면 고만 학습하고 그 결과를 내라는 말 입니다.

13. Learning Rate 조정 정의
이 클래스는 학습하는 동안 정확도를 잘 감시하고 있다가 어느 기준이 되면 학습율을 조정해주는 클래스 입니다.

14. callback 설정
앞서 정의한 두 콜백 클래스를 callbacks에 담아 놓습니다.

15. 개, 고양이를 string으로 변환
아까 파일이름과 개인지 고양이 인지를 저장해놓은 dataframe에서
category를 개인 경우 1로, 고양이 인 경우 0으로 변경해 줍니다.
나중에 one-hot 인코딩으로 변환을 하기 위해서 입니다.

16. train-validation 데이터 분리
이제, train데이터중 20%를 쪼개서 학습중 파라미터 검증을 위한 validation셋을 마련해 놓습니다.

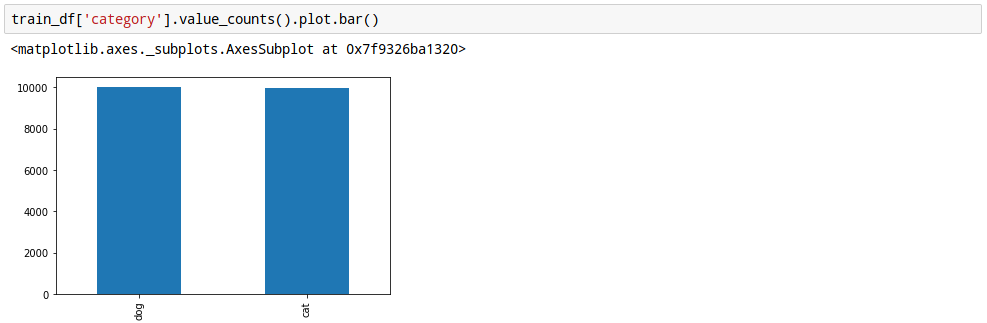
17. train데이터의 분포 확인
train데이터에 존재하는 개와 고양이 수를 그래프로 그려 봅니다.
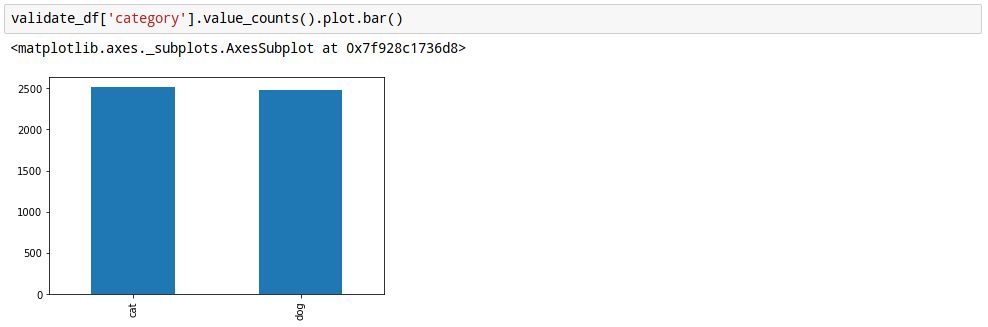
18. validation 분포 확인
아까 잘라낸 20%의 데이터에도 개와 고양이의 분포를 확인 합니다.
19. 학습, 검증데이터의 확인
학습데이터 및 validation의 형상을 확인하고,
한번에 학습할 batch의 size를 설정 합니다.

20. 학습데이터 뻥튀기
아시다 시피 학습은 데이터가 많을수록 잘 될 가능성이 큽니다.
학습데이터를 augmentation해서 수를 늘립니다.
부풀리기는 이미지를 약간 회전시키거나, 줌을 하거나, 상하/좌우 반전을 시키는 방법으로 늘립니다.
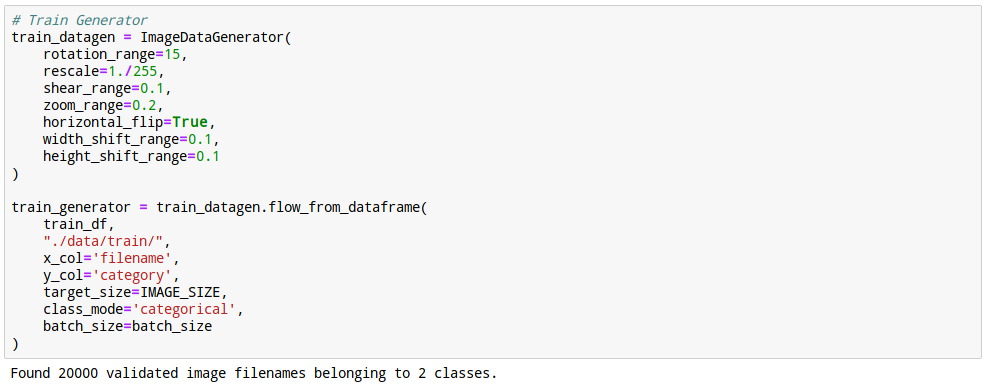
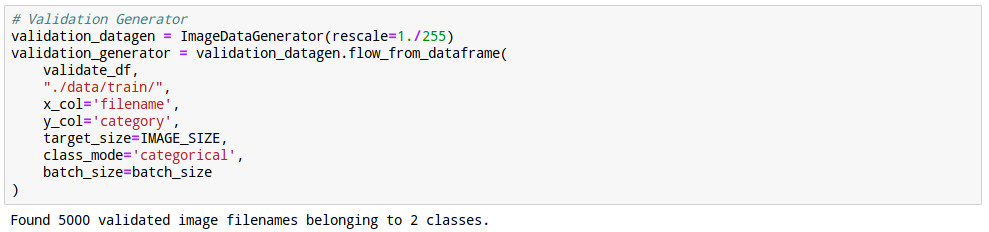
21. Validation데이터 뻥튀기
validation이미지도 마찬가지로 작업을 해줍니다.
22. 샘플 확인
위에 데이터 부풀리기가 잘 되었는지 확인하기 위한 부풀리기를 수행합니다.
23. 이미지 확인
작업된 이미지를 확인 해 봅니다.
자세히 보면 같은 개인데, 좌우 반전이나 줌이 되어 있는걸 볼 수 있죠.
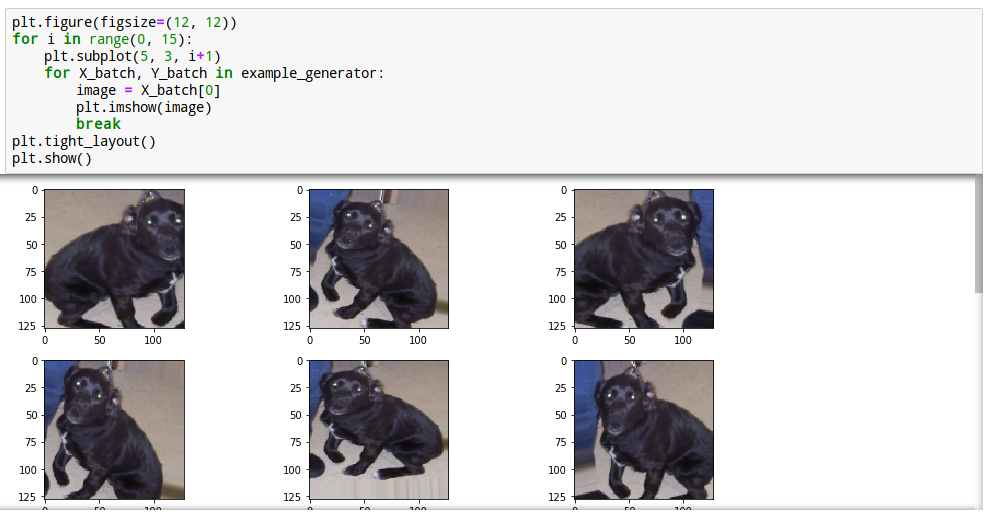
24. 학습시작
자, 이제 학습을 해봅시다.
GPU서버에서 한 Epoch당 대략 5분정도가 걸린거 같습니다.
회사에서 지급된 노트북으로는 15분에서 30분 걸립니다. (곱하기 50번을 해야 함)
휴가 갈때 걸어놓고 가시길...
학습이 잘 되었고 31번째 Epoch에서 ReduceLROnPlateau콜백이 일어났군요.
1e-50 학습율에 도달한 모양입니다.
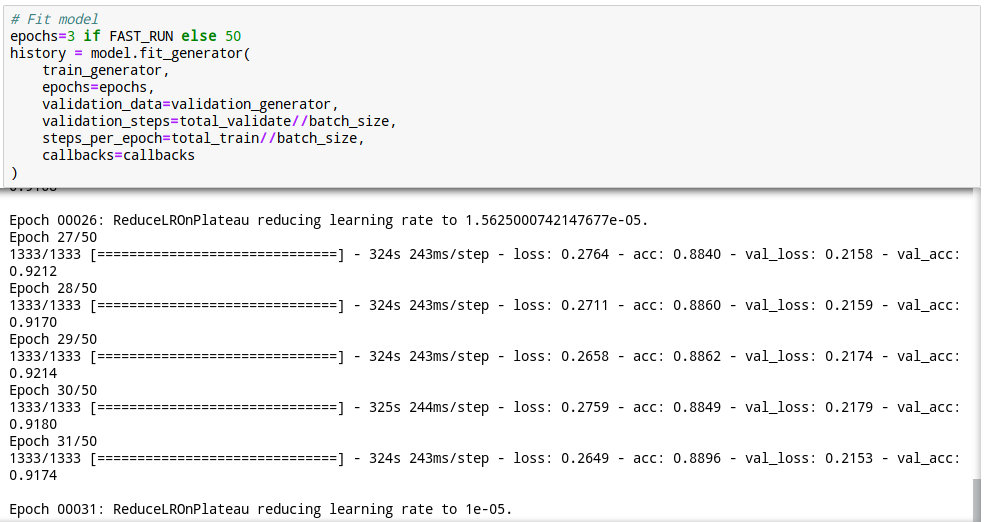
25. 모델 저장
학습이 끝나면, 제일먼저 할일은 모델을 저장하는 것입니다.
모델을 저장해 놓으면, 다음에 24번의 오래오래 걸리는 학습 단계를 생략할 수 있습니다.

26. 학습 내용 확인
이제 그동안 학습시킨 내용을 확인해봐야겠죠.
train loss, validation loss와 train accuracy, validation accuracy 그래프를 그려봅니다.

27. 그래프 확인
아주 예쁘게 잘 확인 된거 같습니다.
파란색 그래프는 학습할때의 그래프고, 빨간색은 validation 그래프 입니다.
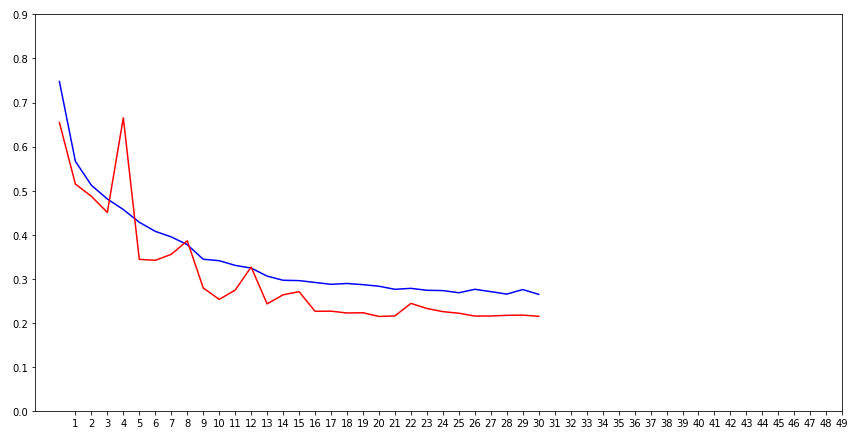
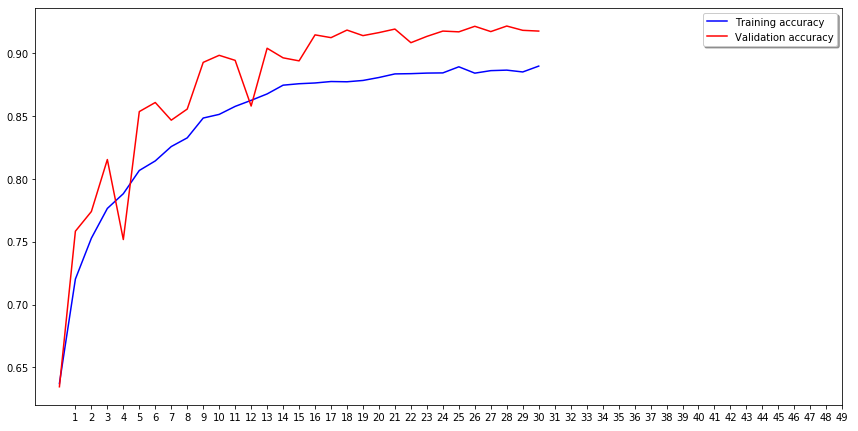
첫번째 그래프를 보면 처음 학습시점에는 오답율이 높다가, 점점 학습을 지속할 수록
오답이 낮아지죠. 그리고 validation도 잘 낮아지고 있습니다.
두번째 그래프는 정확도인데,
마찬가지로 처음 학습 시점에는 정확도가 낮다가 점점 잘 맟춰가는걸 볼 수 있습니다.
중간중간 튀는 부분은 아마도, 개같은 고양이나 고양이짓을 하는 개가 섞여있는거 같습니다.
그래도 train, validation의 차이가 크지 않아서 overfitting이 일어나지 않은것 같네요.
학습도 잘 되었구요.
28. Test
이제 학습된 모델을 가지고 test데이터를 한번 맞춰봅시다.
test1 디렉토리에 있는 개와 고양이 사진으로 한번 평가를 해 봅니다.

29. 평가 데이터 준비
테스트 데이터와 validation데이터와 마찬가지로 데이터를 준비 합니다.
30. 모델 예측
아까 학습한 모델로, 위에서 생성한 test 셋을 넣어 봅니다.

31. 평가 생성
prediction의 결과는 각 record별, 개일확율 얼마, 고양이일 확율 얼마 이런식으로 결과가 담겨져 있습니다.
편의성과 정확도 검증을 위해 개와 고양이일 확률중 보다 큰값에 해당하는 레이블을 선택해서 값을 치환합니다.
(개일 확율 0.73, 고양이일 확률 0.27이면, '개'의 label인 dog을 넣습니다.)

32. 레이블 변환
평가를 위해서 dog, cat 이렇게 들어가 있던 데이터를 다시 1, 0으로 변경합니다.

33. 정답비율 확인
개와 고양이를 어느정도 비율로 예측했는지 한번 살펴 봅니다.
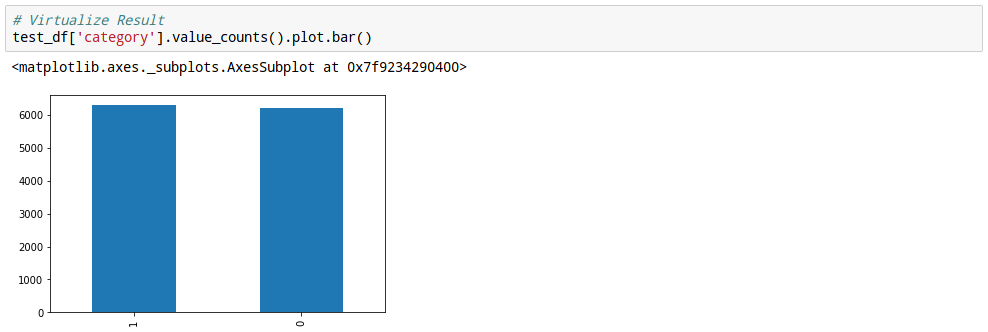
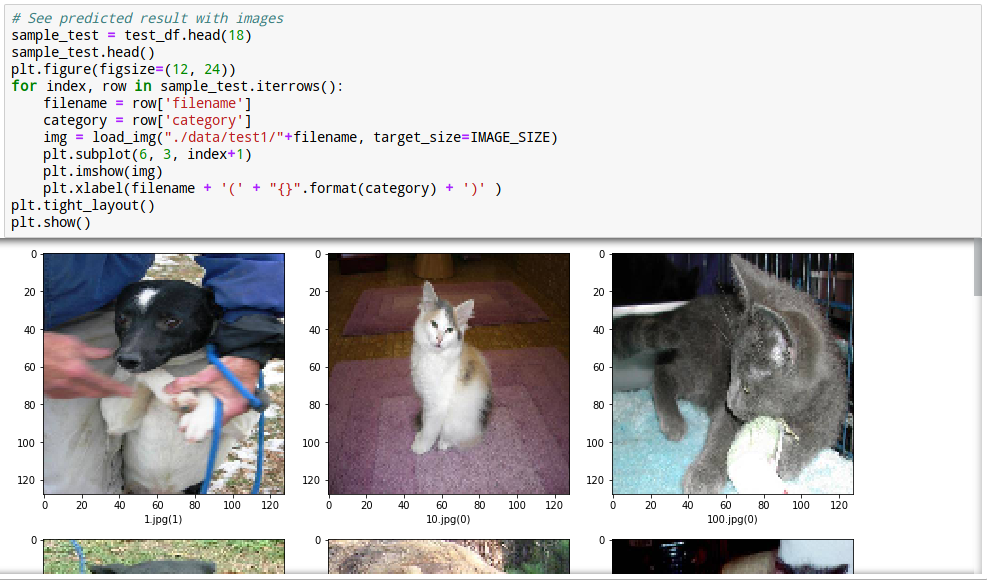
34. 정답 확인
예측한 결과를 눈으로 확인해 봅니다.
잘 맞추네요...
실제로는 더 좋은 모델을 찾기 위해 인고의 시간(몇시간, 몇일씩)을 반복적으로 참아내며
기다리는 인내의 싸움인거 같습니다.
노트북으로 한번 돌려보시면...
AWS나 GCP같은 서비스가 얼마나 고마운지 뼈저리게 느끼실 겁니다. ^^